
Efficient simulations in R
UPDATE (Jun 26): Added Principle 4 and re-ran benchmark using matrices.
Motivation
Being able to code up efficient simulations is one of the most useful skills that you can develop as a social (data) scientist. Unfortunately, it’s also something that’s rarely taught in universities or textbooks.1 This post will cover some general principles that I’ve adopted for writing fast simulation code in R.
I should clarify that the type of simulations that I, personally, am most interested in are related to econometrics. For example, Monte Carlo experiments to better understand when a particular estimator or regression specification does well (or poorly). The guidelines here should be considered accordingly and might not map well on to other domains (e.g. agent-based models or numerical computation).
Our example: Interaction effects in panel models
I’m going to illustrate by replicating a simulation result in a paper that I really like: “Interaction effects in econometrics” by Balli & Sørensen (2013) (hereafter, BS13).
BS13 does various things, but one result in particular has had a big impact on my own research. They show that empirical researchers working with panel data are well advised to demean any (continuous) variables that are going to be interacted in a regression. That is, rather than estimating the model in “level” terms…
\[Y_{it} = \mu_i + \beta_1X1_{it} + \beta_2X2_{it} + \beta_3X1_{it} \cdot X2_{it} + \epsilon_{it}\]… you should estimate the “demeaned” version instead2
\[Y_{it} = \beta_0 + \beta_1 (X1_{it} - \overline{X1}_{i.}) + \beta_2 (X2_{it} - \overline{X2}_{i.}) + \beta_3(X1_{it} - \overline{X1}_{i.}) \cdot (X2_{it} - \overline{X2}_{i.}) + \epsilon_{it}\]Here, $\overline{X1}_{i.}$ refers to mean value of variable $X1$ (e.g. GDP over time) for unit $i$ (e.g. country).
We’ll get to the simulations in a second, but BS13 describe the reasons for their recommendation in very intuitive terms. The super short version — again, you really should read the paper — is that the level model can pick up spurious trends in the case of varying slopes. The implications of this insight are fairly profound… if for no other reason that so many applied econometrics papers employ interaction terms in a panel setting.3
Okay, so a potentially big deal. But let’s see a simulation and thereby get the ball rolling for this post. I’m going to run a simulation experiment that exactly mimics one in BS13 (see Table 3). We’ll create a fake dataset where the true interaction is ZERO. However, the slope coefficient of one of the parent terms varies by unit (here: country). If BS13 is right, then including an interaction term in our model could accidentally result in a spurious, non-zero coefficient on this interaction term. The exact model is
\[y_{it} = \alpha + x_{1,it} + 1.5x_{2,it} + \epsilon_{it}\]Data generating function
It will prove convenient for me to create a function that generates an instance of the experimental dataset — i.e. corresponding to one simulation run — which is what you see in the code below. The exact details are not especially important. (I’m going to coerce the return object into a data.table instead of standard data frame, but I’ll get back to that later.) For now, just remember that the coefficient on any interaction term should be zero by design. I’ll preview the resulting dataset at the end of the code.
library(data.table)
## Convenience function for generating our experimental panel data. Takes a
## single argument: `sims` (i.e. how many simulation runs to do we want; defaults
## to 1).
gen_data = function(sims=1) {
## Total time periods in the the panel = 500
tt = 500
sim = rep(rep(1:sims, each = 10), times = 2) ## Repeat twice b/c we have two countries
## x1 covariates
x1_A = 1 + rnorm(tt*sims, 0, 1)
x1_B = 1/4 + rnorm(tt*sims, 0, 1)
## Add second, nested x2 covariates for each country
x2_A = 1 + x1_A + rnorm(tt*sims, 0, 1)
x2_B = 1 + x1_B + rnorm(tt*sims, 0, 1)
## Outcomes (notice different slope coefs for x2_A and x2_B)
y_A = x1_A + 1*x2_A + rnorm(tt*sims, 0, 1)
y_B = x1_B + 2*x2_B + rnorm(tt*sims, 0, 1)
## Combine in a data table (basically just an enhanced data frame)
dat =
data.table(
sim,
id = as.factor(c(rep('A', length(x1_A)), rep('B', length(x1_B)))),
x1 = c(x1_A, x1_B),
x2 = c(x2_A, x2_B),
y = c(y_A, y_B)
)
## Demeaned covariates (grouped by country and simulation)
dat[,
`:=` (x1_dmean = x1 - mean(x1),
x2_dmean = x2 - mean(x2)),
by = .(sim, id)][]
## Optional set order i.t.o sims
setorder(dat, sim)
return(dat)
}
## Generate an instance of the data (using the default arguments)
set.seed(123)
d = gen_data()
d## sim id x1 x2 y x1_dmean x2_dmean
## 1: 1 A 0.4395244 0.4437 0.3716 -0.59507 -1.61707
## 2: 1 A 0.7698225 0.7299 1.7366 -0.26477 -1.33092
## 3: 1 A 2.5587083 3.5407 5.5578 1.52412 1.47994
## 4: 1 A 1.0705084 1.9383 4.2281 0.03592 -0.12246
## 5: 1 A 1.1292877 -0.4201 0.8834 0.09470 -2.48085
## ---
## 996: 1 B 0.1600248 1.2367 3.6943 -0.08764 -0.06973
## 997: 1 B 1.3205160 2.5757 6.0264 1.07285 1.26929
## 998: 1 B -1.1011004 0.1763 -1.1776 -1.34877 -1.13005
## 999: 1 B -0.2726167 1.2642 3.4449 -0.52028 -0.04216
## 1000: 1 B 0.0008093 0.5403 1.9158 -0.24686 -0.76607Let’s run some regressions on one simulated draw of our dataset. Since this is a panel model, I’ll use the (incredible) fixest package to control for country (“id”) fixed-effects.
library(fixest)
mod_level = feols(y ~ x1 * x2 | id, d)
mod_dmean = feols(y ~ x1_dmean * x2_dmean | id, d)
etable(mod_level, mod_dmean, se = 'standard')## mod_level mod_dmean
## Dependent Var.: y y
##
## x1 1.195*** (0.0650)
## x2 1.638*** (0.0394)
## x1 x x2 -0.1373*** (0.0187)
## x1_dmean 0.9544*** (0.0577)
## x2_dmean 1.556*** (0.0388)
## x1_dmean x x2_dmean 0.0199 (0.0213)
## Fixed-Effects: ------------------- ------------------
## id Yes Yes
## ___________________ ___________________ __________________
## S.E. type Standard Standard
## Observations 1,000 1,000
## R2 0.86768 0.86062
## Within R2 0.86761 0.86055Well, there you have it. The “level” model spuriously yields a statistically significant coefficient on the interaction term. In comparison, the “demeaned” version avoids this trap and also appears to have better estimated the parent term coefficients.
Cool. But to really be sure, we should repeat our simulation many times. (BS13 do it 20,000 times…) And, so, we now move on to the main purpose of this post: How do we write simulation code that efficiently completes tens of thousands of runs? Here follow some key principles that I try to keep in mind.
Principle 1: Trim the fat
Subtitle: lm.fit() is your friend
The first key principle for writing efficient simulation code is to trim the fat as much as possible. Even small differences start to add up once you’re repeating operations tens of thousands of times. For example, does it really make sense to use fixest::feols() for this example data? As much as I am a huge fixest stan, in this case I have to say… no. The package is optimised for high-dimensional fixed-effects, clustered errors, etc. Our toy dataset contains just one fixed-effect (comprising two levels) and we are ultimately only interested in extracting a single coefficient for our simulation. We don’t even need to save the standard errors. Most of fixest’s extra features are essentially wasted. We could probably do better just by using a simple lm() call and specifying the country fixed-effect (“id”) as a factor.
However, lm() objects still contain quite a lot of information (and invoke extra steps) that we don’t need. We can simplify things even further by directly using the fitting function that lm calls underneath the hood. Specifically, the lm.fit() function. This requires a slightly different way of writing our regression model — closer to matrix form — but yields considerable speed gains. Here’s a benchmark to demonstrate.
library(microbenchmark)
microbenchmark(
feols = feols(y ~ x1_dmean * x2_dmean | id, d),
lm = lm(y ~ x1_dmean * x2_dmean + id, d),
lm.fit = lm.fit(cbind(1, d$x1_dmean, d$x2_dmean, d$x1_dmean*d$x2_dmean, d$id), d$y),
times = 2
)## Unit: microseconds
## expr min lq mean median uq max neval cld
## feols 4684.2 4684.2 4696.9 4696.9 4709.6 4709.6 2 b
## lm 967.0 967.0 1627.2 1627.2 2287.4 2287.4 2 a
## lm.fit 112.2 112.2 114.7 114.7 117.2 117.2 2 aFor this small dataset example, a regular lm() call is about five times faster than feols()… and lm.fit() is a further ten times faster still. Now, we’re talking microseconds here and the difference is not something you’d notice running a single regression. But… once you start running 20,000 of them, then those microseconds start to add up.4 Final thing, just to prove that we’re getting the same coefficients:
coef(lm.fit(cbind(1, d$x1_dmean, d$x2_dmean, d$x1_dmean*d$x2_dmean, d$id), d$y))## x1 x2 x3 x4 x5
## 3.16117 0.95435 1.55596 0.01993 -0.14978The output is less visually appealing a regular regression summary, but we can see the interaction term coefficient of 0.01993247 in the order in which it appeared (i.e. “x4”). FWIW, you can also name the coefficients in the design matrix if you wanted to make it easier to reference a coefficient by name. This is what I’ll be doing in the full simulation right at the end.
coef(lm.fit(cbind('intercept' = 1, 'x1' = d$x1_dmean, 'x2' = d$x2_dmean, 'x1:x2' = d$x1_dmean*d$x2_dmean, 'id' = d$id), d$y))## intercept x1 x2 x1:x2 id
## 3.16117 0.95435 1.55596 0.01993 -0.14978Principle 2: Generate your data once
Subtitle: It’s much quicker to generate one large dataset than many small ones
One common bottleneck I see in a lot of simulation code is generating a small dataset for each new run of a simulation. This is much less efficient that generating a single large dataset that you can either sample from during each iteration, or subset by a dedicated simulation ID. We’ll get to iteration next, but this second principle really stems from the same core idea: vectorisation in R is much faster than iteration. Here’s a simple benchmark to illustrate, where we generate data for a 100 simulation runs. Note that the relative difference would keep growing as we added more simulations.
microbenchmark(
many_small = lapply(1:100, gen_data),
one_big = gen_data(100),
times = 2
)## Unit: milliseconds
## expr min lq mean median uq max neval cld
## many_small 1391.91 1391.91 1640.19 1640.19 1888.47 1888.47 2 b
## one_big 25.26 25.26 26.04 26.04 26.81 26.81 2 aPrinciple 3: Go parallel or nest
Subtitle: Let data.table and co. handle the heavy lifting
The standard approach to coding up a simulation is to run everything as an iteration, either using a for() loop or an lapply() call. Experienced R programmers are probably reading this section right now and thinking, “Even better; run everything in parallel.” And it’s true. A Monte Carlo experiment like the one we’re doing here is ideally suited to parallel implementation, because each individual simulation run is independent. It’s a key reason why Monte Carlo experiments are such popular tools for teaching parallel programming concepts. (Guilty as charged.)
But any type of explicit iteration — whether it is a for() loop or an lapply() call, or whether it is run sequentially or in parallel — runs up against the same problem as we saw in Principle 2. Specifically, it is slower than vectorisation. So how can we run our simulations in vectorised fashion? Well, it turns out there is a pretty simple way that directly leverages Principle 2’s idea of generating one large dataset: We nest our simulations directly in our large data.table or tibble.
Hadley and Garret’s R for Data Science book has a nice chapter on model nesting with tibbles, and then Vincent has a cool blog post replicating the same workflow with data.table. But, really, the core idea is pretty simple: We can use the advanced data structure and functionality of tibbles or data.tables to run our simulations as grouped operations (i.e. by simulation ID). In other words, just like we can group a data frame and then collapse down to (say) mean values, we can also group a data frame and then run a regression on each subgroup.
Why might this be faster than explicit parallel iteration? Well, basically it boils down to the fact that data.tables and tibbles provide an enhanced structure for returning complex objects (including list columns) and their grouped operations are highly optimised to run in (implicit) parallel at the C++ level.5 The internal code of data.table, in particular, is just so insanely optimised that trying to beat it with some explicit parallel loop can be a fool’s errand.
Okay, so let’s see a benchmark. I’m going to compare three options for simulating 100 draws: 1) sequential iteration with lapply(), 2) explicit parallel iteration with parallel::mclapply, and 3) nested (implicit parallel) iteration. For the latter, I’m simply grouping my dataset by simulation ID and then leveraging data.table’s powerful .SD syntax.6 Note further than I’m going to run regular lm() calls rather than lm.fit() — see Principle 1 — because I want to keep things simple and familiar for the moment.
library(parallel) ## For parallel::mclapply
## Generate dataset with 1000 simulation draws
set.seed(123)
d = gen_data(100)
microbenchmark(
sequential = lapply(1:max(d$sim),
function(i) coef(lm(y ~ x1 * x2 + id, d[sim==i]))['x1:x2']
),
parallel = mclapply(1:max(d$sim),
function(i) coef(lm(y ~ x1 * x2 + id, d[sim==i]))['x1:x2'],
mc.cores = detectCores()
),
nested = d[, coef(lm(y ~ x1 * x2 + id, .SD))['x1:x2'], by = sim],
times = 2
)## Unit: milliseconds
## expr min lq mean median uq max neval cld
## sequential 141.90 141.90 155.31 155.31 168.72 168.72 2 b
## parallel 104.04 104.04 105.25 105.25 106.46 106.46 2 a
## nested 84.41 84.41 88.18 88.18 91.95 91.95 2 aOkay, not a huge difference between the three options for this small benchmark. But — trust me — the difference will grow for the full simulation where we’re comparing the level vs demeaned regressions with UPDATE: Upon reflection, I’m not being quite fair to lm.fit().mclapply() here, because it is being penalised for overhead on a small example. But I definitely stand by my next point. There are also some other reasons why relying on data.table will help us here. For example, parallel::mclapply() relies on forking, which is only available on Linux or Mac. Sure, you could use a different package like future.apply to provide a parallel backend (PSOCK) for Windows, but that’s going to be slower. Really, the bottom line is that we can outsource all of that parallel overhead to data.table and it will automatically handle everything at the C(++) level. Winning.
Principle 4: Use matrices for an extra edge
Subtitle: Save your simulation from having to do extra conversion work
The primary array format of empirical work is the data frame. It’s what we all use, really, so there’s no point expanding on that. (TL;DR data frames are just very convenient for humans to work with and reason about.) However, regressions are run on matrices. Which is to say that when you run a regression in R — and most other languages for that matter — behind the scenes your input data frame is first converted to an equivalent matrix before any computation gets done. Matrices have several features that make them “faster” to compute on than data frames. For example, every element must be of the same type (say, numeric). But let’s just agree that converting a data frame to a matrix requires at least some computational effort. Consider then what happens when we feed our lm.fit() function a pre-created design matrix, instead asking it to convert a bunch of data frame columns on the fly.
set.seed(123)
d = gen_data()
X = cbind(intercept = 1, x1 = d$x1_dmean, x2 = d$x2_dmean, 'x1:x2' = d$x1_dmean*d$x2_dmean, id = d$id)
Y = d$y
microbenchmark(
lm.fit = lm.fit(cbind(1, d$x1_dmean, d$x2_dmean, d$x1_dmean*d$x2_dmean, d$id), d$y),
lm.fit_mat = lm.fit(X, Y),
times = 5
)## Unit: microseconds
## expr min lq mean median uq max neval cld
## lm.fit 66.56 69.56 121.1 70.27 75.00 323.96 5 a
## lm.fit_mat 49.81 49.81 52.3 50.34 51.79 59.72 5 aWe’re splitting hairs at this point. I mean, what’s 20 microseconds between friends? And, yet, these 20 microseconds translate to a roughly 40% improvement in relative terms. As I keep saying, even microseconds add up once you multiply them by a couple thousand.
“Okay, Grant.” I can already you you saying. “You just told us to use data.tables and now you’re telling us to switch to matrices. Which is it, man?!” Well, remember what I said earlier about the enhanced structure that data.tables (and tibbles) offer us. We can easily create a list column of matrices inside a data.table (or tibble). We could have done this directly in the gen_data() function. But I’m going to leave that function as-is, and show you how simple it is to collapse columns of an existing data.table into a matrix list column. Once more we’ll use a standard grouped operation — where we are grouping by sim — to do the work:
d = d[,
.(Y = list(y),
X_level = list(cbind(intercept = 1, x1 = x1, x2 = x2, 'x1:x2' = x1_dmean*x2_dmean, id = id)),
X_dmean = list(cbind(intercept = 1, x1 = x1_dmean, x2 = x2_dmean, 'x1:x2' = x1_dmean*x2_dmean, id = id))),
by = sim]
d## sim Y
## 1: 1 0.3716,1.7366,5.5578,4.2281,0.8834,6.8554,...
## X_level
## 1: 1.000000, 1.000000, 1.000000, 1.000000, 1.000000, 1.000000, 0.439524, 0.769823, 2.558708, 1.070508, 1.129288, 2.715065, 0.443726, 0.729867, 3.540728, 1.938333,-0.420055, 4.755638, 0.962261, 0.352386, 2.255598,-0.004398,-0.234929, 4.528622, 1.000000, 1.000000, 1.000000, 1.000000, 1.000000, 1.000000,...
## X_dmean
## 1: 1.000000, 1.000000, 1.000000, 1.000000, 1.000000, 1.000000,-0.595066,-0.264768, 1.524118, 0.035918, 0.094697, 1.680475,-1.617066,-1.330924, 1.479937,-0.122458,-2.480846, 2.694847, 0.962261, 0.352386, 2.255598,-0.004398,-0.234929, 4.528622, 1.000000, 1.000000, 1.000000, 1.000000, 1.000000, 1.000000,...I know the printed output looks a little different, but the key thing to know is that each simulation is now represented by a single row. In this case, we only have one simulation, so our whole data table consists of just one row. Moreover, those fancy list columns contain all of the 500 panel observations — in matrix form — that we need run our regressions. To access whatever is inside one of the list columns, we “unnest” very simply by extracting the first element with brackets, i.e. [[1]]. For example, to extract the Y column of our single simulation dataset, we could do:
head(d$Y[[1]]) ## Just show the first few rows## [1] 0.3716 1.7366 5.5578 4.2281 0.8834 6.8554If you’d like to know more about this approach, than I highly recommend Vincent’s aforementioned blog post on the topic. The very last thing I’m going to show you here (since we’ll soon be adapting it to run our full simulation), is how easily everything carries over to operations inside a nested data table. In short, we just use the magic of .SD again:
d[, head(.SD$Y[[1]]), by = sim]## sim V1
## 1: 1 0.3716
## 2: 1 1.7366
## 3: 1 5.5578
## 4: 1 4.2281
## 5: 1 0.8834
## 6: 1 6.8554Putting it all together
Time to put everything together and run this thing. Like BS13, I’m going to simulate 20,000 runs. I’ll print the time it takes to complete the full simulation at the bottom.
set.seed(123)
## Generate our large dataset of 20k simulations
d = gen_data(2e4)
## Optional: Set key for better collapse performance
setkey(d, sim)
## Collapse into a nested data.table (1 row per simulation), with matrix list columns
d = d[,
.(Y = list(y),
X_level = list(cbind(intercept = 1, x1 = x1, x2 = x2, 'x1:x2' = x1*x2, id = id)),
X_dmean = list(cbind(intercept = 1, x1 = x1_dmean, x2 = x2_dmean, 'x1:x2' = x1_dmean*x2_dmean, id = id))),
by = sim]
## Run our simulation
tic = Sys.time()
sims = d[,
.(level = coef(lm.fit(.SD$X_level[[1]], .SD$Y[[1]]))['x1:x2'],
dmean = coef(lm.fit(.SD$X_dmean[[1]], .SD$Y[[1]]))['x1:x2']),
by = sim]
Sys.time() - tic## Time difference of 2.669 secsAnd look at that. Just over 2 seconds to run the full 20k simulations! (Can you beat that? Let me know in the comments… UPDATE: Turns out you can thanks to the even faster .lm.fit() function. See follow-up post here.)
All that hard work deserves a nice plot, don’t you think?
par(family = 'HersheySans') ## Optional: Nice font for (base) plotting
hist(sims$level, col = scales::alpha('skyblue', .7), border=FALSE,
main = 'Simulating interaction effects in panel data',
xlim = c(-0.3, 0.2),
xlab = 'Coefficient values',
sub = '(True value is zero)')
hist(sims$dmean, add=TRUE, col = scales::alpha('red', .5), border=FALSE)
abline(v = 0, lty = 2)
legend("topright", col = c(scales::alpha(c('skyblue', 'red'), .5)), lwd = 10,
legend = c("Level", "Demeaned"))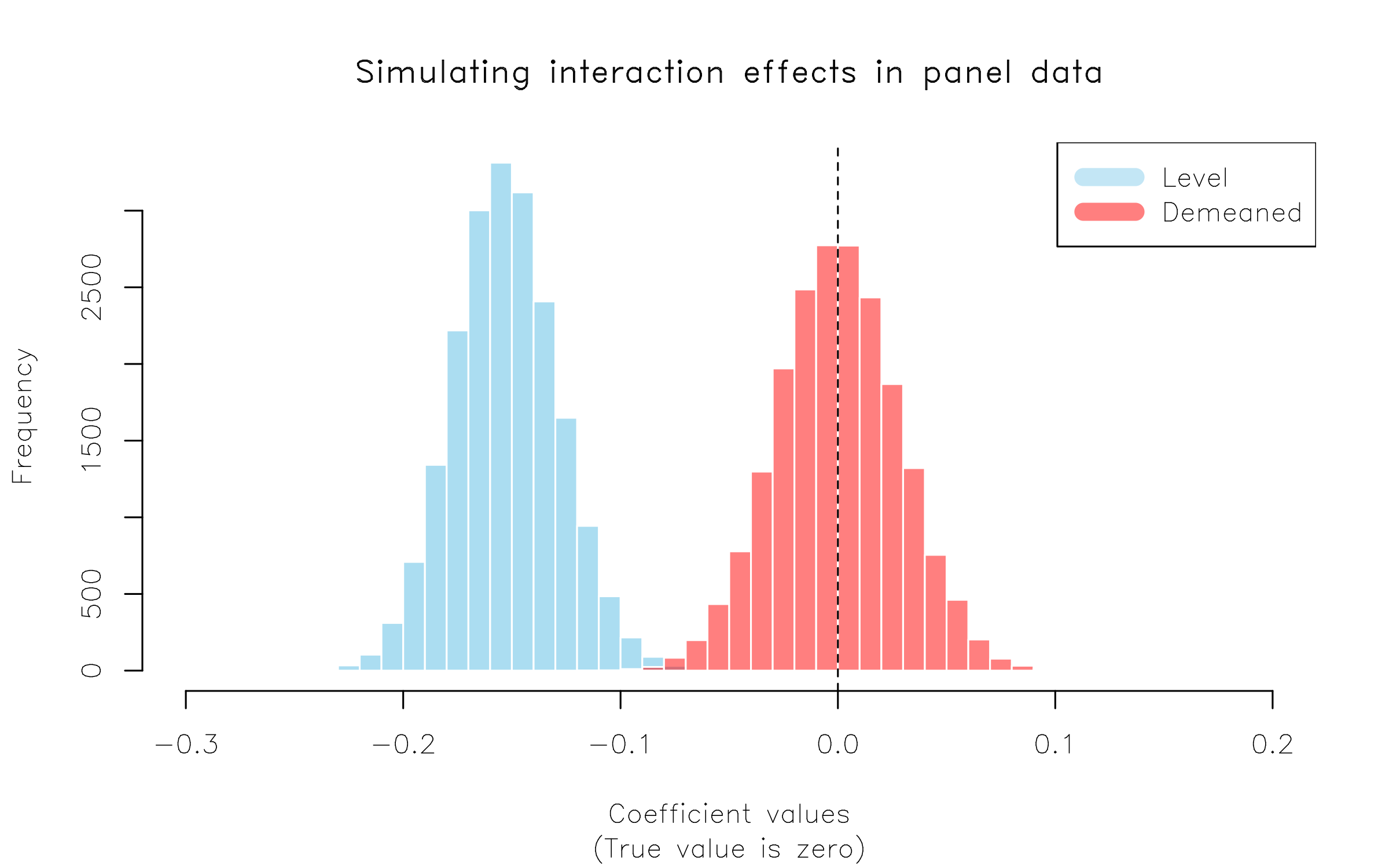
Here we have replicated the key result in BS13, Table 3. Moral of the story: If you have an interaction effect in a panel setting (e.g. DiD!), it’s always worth demeaning your terms and double-checking that your results don’t change.
Conclusion
Being able to write efficient simulation code is a very valuable skill. In this post we have replicated an actual published result, incorporating several principles that have served me well:
-
Trim the fat (Subtitle:
lm.fit()is your friend.) -
Generate your data once (Subtitle: It’s much quicker to generate one large dataset than many small ones)
-
Go parallel or nest (Subtitle: Let data.table and co. handle the heavy lifting)
-
Use matrices for an extra edge (Subtitle: Save your simulation from having to do extra conversion work)
You certainly don’t have to adopt all of these principles to write your own efficient simulation code in R. There may even be cases where it’s more efficient to do something else. But I’m confident that incorporating at least one or two of them will generally make your simulations much faster.
P.S. If you made it this far and still need convincing that simulations are awesome, watch John Rauser’s incredible talk, “Statistics Without The Agonizing Pain”.
References
Balli, Hatice Ozer, and Bent E. Sørensen. “Interaction effects in econometrics.” Empirical Economics 45, no. 1 (2013): 583-603. Link
-
Ed Rubin and I are writing a book that will attempt to fill this gap, among other things. Stay tuned! ↩
-
In their notation, BS13 only demean the interacted terms on $\beta_3$. But demeaning the parent terms on $\beta_1$ and $\beta_2$ is functionally equivalent and, as we shall see later, more convenient when writing the code since we can use R’s
*expansion operator to concisely specify all of the terms. ↩ -
Got a difference-in-differences model that uses twoway fixed-effects? Ya, that’s just an interaction term in a panel setting. In fact, the demeaning point that BS13 are making here — and actually draw an explicit comparison to later in the paper — is equivalent to the argument that we should control for unit-specific time trends in DiD models. The paper includes additional simulations demonstrating this equivalence, but I don’t want to get sidetracked by that here. ↩
-
Another thing is that
lm.fit()produces a much more limited, but leaner return object. We’ll be taxing our computer’s memory less as a result. ↩ -
That’s basically all that vectorisation is; i.e. a loop implemented at the C(++) level. ↩
-
This will closely mimic a related example in the data.table vignettes, which you should read if you’re interested to learn more. ↩
Comments